一些功能的理解
功能说明
加载预定义敏感词
在static目录创建sensitive.txt文件,每行一个敏感词;
这些敏感词会在系统启动时自动加载;
static 目录在和 reman 程序同级目录;
2024年12月6日更新:添加新词需要重启程序;
加载预定义黑名单
在软件根目录创建blacklist.txt文件,每行一个IP,不支持IP段;
这些IP会在系统启动时自动加载,并加入黑名单;
在
v1.4.1及以上版本中提供
导入资源说明
想要自定义导入资源的名称,填入导入框中的内容可以遵循以下格式:
「资源名称1」 链接1
「资源名称2」 链接2
「资源名称3」 链接3系统会自动解析名称,然后使用指定的名称入库;
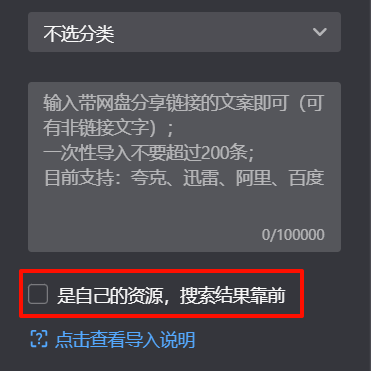
游客、用户不支持选择分类,也不支持自定义资源名称;
2024年12月4日更新:也即是说需要导入时启用“是自己的资源,搜索结果靠前”
站点验证问题
一般而言,都会提供2种方式:
- meta标签验证
- 文件验证
meta标签验证:
<meta name="remansite" content="1234567890" />将类似上面的代码,放在【站点配置】=》【基本配置】中的统计代码中;
文件验证:
将文件放在reman同级目录下的static目录下,这样就可以通过https://你的域名/xxx.txt之类的链接访问;
reman同级目录指:二进制文件reman的目录,比如说是:
/root/app/,那么static目录就是/root/app/static/;
缓存问题
发生错误啦~~,也许这是个临时错误,可以尝试刷新一下
更新程序后,若见到类似错误:
- 首先,尝试清空浏览器缓存(强制刷新浏览器),若问题解决,则不需要再往下看;
- 若问题依旧,说明反向代理存在缓存,需要关闭反向代理的缓存设置
- 如宝塔就有反向代理有缓存的设置;
- 若你开启了Cloudflare的Proxy(小黄云),可能也会造成该问题,请自行查看Cloudflare的设置解决,或者付费请我帮忙;
样式重写问题
后台【站点配置】=>【样式设置】,可以自定义样式;
但是你会发现,reman的样式是类似随机生成的,有一串随机码;
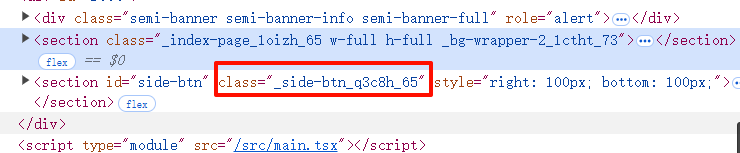
那么,如何重写样式呢?
你可以使用如下语法:
[class^="_side-btn"] {
background-color: #ff0000;
}意思就是说,reman自带的样式随机码是在末尾,但是前面的部分是固定的,所以,你可以通过这种方式,重写样式;
顺带一提,后台【站点配置】=>【样式设置】,需要自己加上
<style>标签,否则不会生效;
CDN防火墙问题
注意,使用CDN不能缓存 首页(index),否则程序更新时,可能会出现问题(比如:缓存问题)
防火墙问题:
如果你启用了某些防火墙,可能在进行后台更新时,会出现问题。特别是添加站点统计代码之类的,会出现更新失败的情况;
可以先关闭防火墙,然后再进行操作,操作完毕后,再开启防火墙;
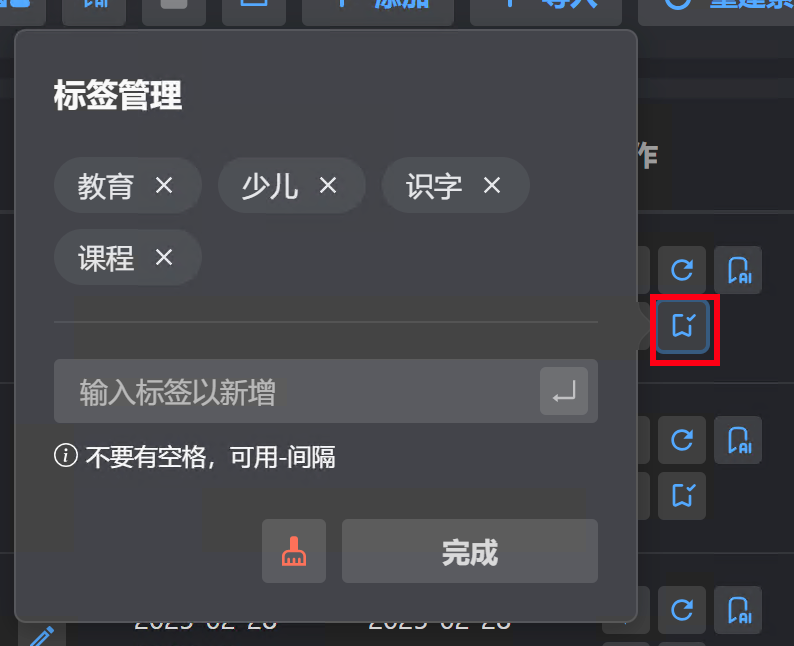
标签聚合功能
预计在版本 >=1.5.0 中添加标签管理及聚合页功能;
管理标签:
聚合页:
目前可从如下页面,点击进入聚合页:
- 详情页
- 搜索列表
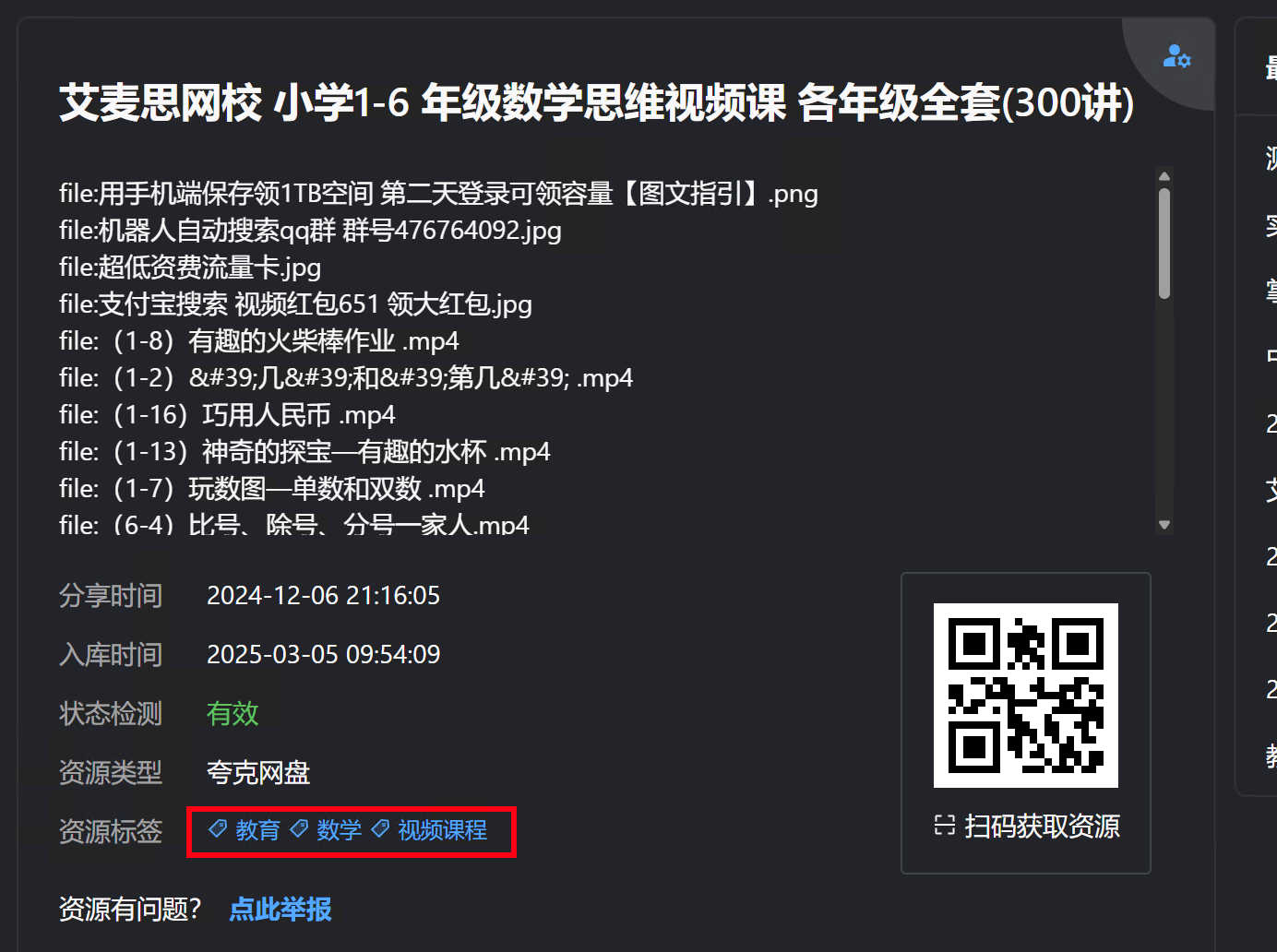
聚合页展示效果:
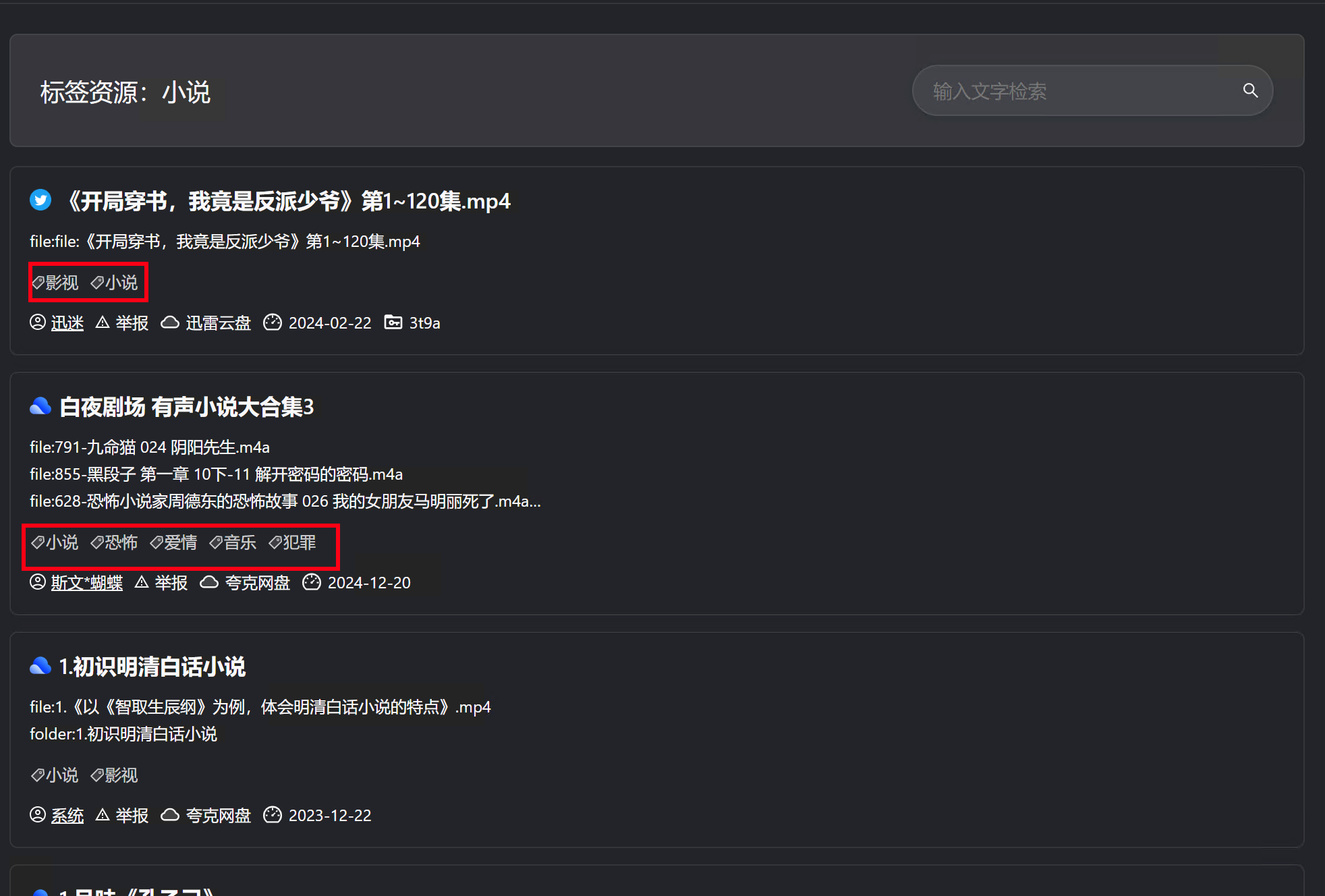
tips: 现在支持历史资源标签生成,可以在资源列表中点击相应按钮,生成历史资源的标签;
配置相关
检查失效资源功能
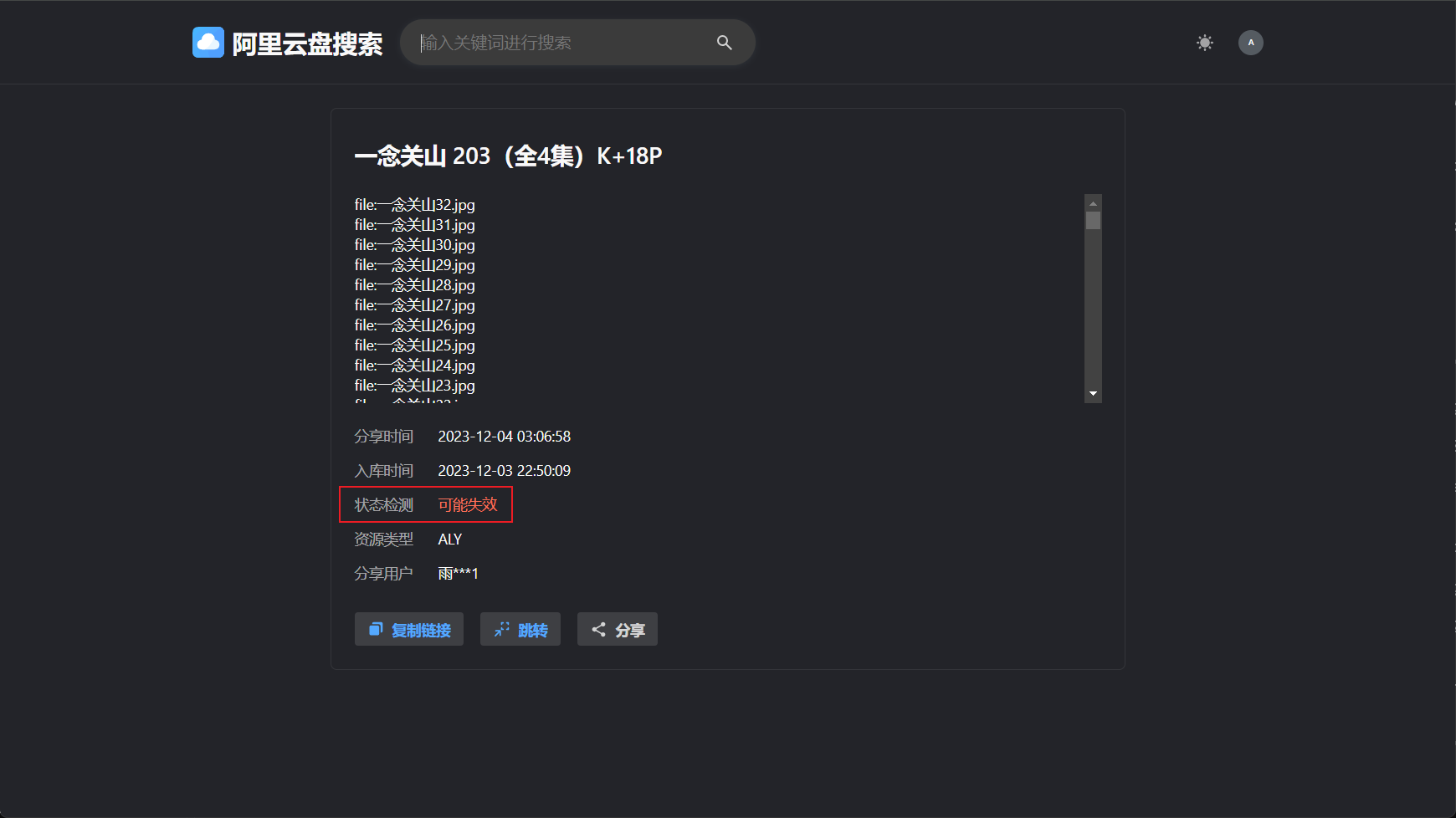
描述:
开启后,在详情页面,会在页面中显示资源是否有效:
当检测到失效链接时,自动从索引中删除
此功能,需要“检查失效资源功能”开启,否则不会生效;
描述:
在详情页面,如果检测到失效链接,系统会自动从索引中删除;
是否在资源失效时搜索同名资源
如果资源失效,则会在详情页面,显示同名资源的搜索结果;
开启失效资源跳转搜索页面
如果资源失效,则会用失效资源的名称作为搜索词,跳转到搜索页面;
注:该功能的优选级高于“是否在资源失效时搜索同名资源”;
用户/游客是否可以导入资源
如果开启,则用户/游客可以导入资源;会在首页显示导入资源的按钮;
首页展示搜索推荐词
如果开启,则会在首页展示搜索推荐词;
“搜索推荐词”通过“列表管理”添加;
首页展示影视推荐词
如果开启,则会在首页展示影视推荐词; “影视推荐词”通过【热门管理】=> “影视热词”添加;
禁用影视搜索
开启后,会屏蔽大部分影视资源;
如果需要迁移旧数据(因为该功能需要全文索引的支持),如果版本<0.2.1 需要先“重建索引”,然后运行如果命令:
./reman fix rel-movie移除相似的影视资源
背景:有些用户会把同个资源生成多个分享链接,导致某页搜索结果中,同用户的相似资源过多,影响用户体验;
可以通过此功能,移除相似的影视资源;
系统后台定期检测,如果发现相似资源,则会移除;
不收录重复资源
有一些用户将同一份资源,通过多次分享生成了不同的分享链接,但这还是属于同一份资源;
开启该选项,系统会自动检测,如果发现资源名称和用户名已经存在,则不再收录;
详情页描述模板
利用该功能,可以自定义详情页的描述( description );
模板中支持的变量:
%site_name%: 站点名称%site_title%: 站点标题%disk_name%: 资源名称%disk_type%: 资源类型%disk_link%: 资源链接%disk_files%: 资源文件列表%disk_share_time%: 资源分享时间%disk_create_time%: 资源入库时间%disk_update_time%: 资源更新时间
注意: 系统会截断 150 个字符,超出部分会被截断;
详情页 h1 标题模板
支持的变量和上面 "详情页描述模板" 一致,参考上面;
注意: 系统截断 60 个字符;
详情页标题模板
支持的变量和上面 "详情页描述模板" 一致,参考上面;
注意: 系统截断 60 个字符;
影视页标题模板
利用该功能,可以自定义影视页的 h1 标题(伪);
模板中支持的变量:
%site_name%: 站点名称%site_title%: 站点标题%film_name%: 影视名称%film_desc%: 影视描述%film_show%: 影视元信息
影视页关键词模板
利用该功能,可以自定义影视页的关键词( keywords );
模板中支持的变量:
%site_name%: 站点名称%site_title%: 站点标题%film_name%: 影视名称%film_desc%: 影视描述%film_show%: 影视元信息
注意:系统会截断 5 个关键词(以, 区分);
影视页描述模板
利用该功能,可以自定义详情页的描述( description );
模板中支持的变量:
%site_name%: 站点名称%site_title%: 站点标题%film_name%: 影视名称%film_desc%: 资源描述
注意: 系统会截断 150 个字符,超出部分会被截断;
达人页描述模板
利用该功能,可以自定义达人页的描述( description );
模板中支持的变量:
%site_name%: 站点名称%site_title%: 站点标题%user%: 用户名称
达人页标题模板
支持的变量和上面 "达人页描述模板" 一致,参考上面;
生成 SEO 的类型
div: 生成 div 标签,div 标签的 style="display:none";noscript: 生成 noscript 标签,noscript 是告诉浏览器/搜索引擎,当不支持 JavaScript 时,显示的内容;
资源重复提交检测
启用后将检测资源是否已经被提交过,提交过不再入库(不管曾经是否成功入库);
用途:如果开启“游客提交资源”,但是没收录他的资源(原因很多,比如在分享黑名单内),可以通过此功能,防止他再次提交;
因为他每次提交,都会去请求网盘 API,防止网盘方封禁服务器 IP;
迅雷联盟参数
https://pan.xunlei.com/s/VNsHuHdNO9yps5RKluFymQImA1?origin=lpss&pwd=z7sg
和
https://pan.xunlei.com/s/VNsHuHdNO9yps5RKluFymQImA1?pwd=z7sg&origin=lpss
是等价的,都是可以计算收益的,不要来问我说:“迅雷官方说,参数只能在密码后面,参数只能放在最后”。迅雷拉新的这些官方人员,并不是技术人员;
遇到这些问题,不要和我犟,和我犟,只能算你赢,我也只能送你一个消息免打扰套餐
禁止搜索引擎索引详情页
对于网盘搜索网站来说,资源重复性太高了,很容易被搜索引擎 K 掉;
所以,可以通过此功能,禁止搜索引擎索引详情页;
这会在 html 的 head 中,添加:
<meta name="robots" content="noindex" />封掉详情页后,还有影视页面不会受影响;
下列情况,不会添加 noindex:
- 该资源为自己的资源
- 该资源被单独设置为可索引
- [预计版本>0.3.5] 入库时判断资源重复性,在重复资源列表中,会将一个资源移除noindex(优先是自己的资源);我将这称为“智能 noindex”
通过 AI 生成介绍文章
你需要先配置 Gemini API,KEY,然后开启此功能;
开启后,可以索引的资源,会自动生成介绍文章;(也即是说,想要使用该功能,你还需要开启【禁止搜索引擎索引详情页】)
gemini 的 Key:
需要在:https://makersuite.google.com/app/apikey 申请
另外 ,API 地址是:https://generativelanguage.googleapis.com/v1beta/models/gemini-pro:generateContent
但是,由于众所周知的原因,这个 API 地址是不稳定的,所以,你需要参照这篇文章的内容,自己搭建一个:https://zhile.io/2023/12/24/gemini-pro-proxy.html
当然,我是自己搭建了一个,实际上可以用我的,我不知道多人使用会不会被封,所以,你需要付费使用,¥ 100 一次性买断(Api-Key 还是需要你自己申请)。
提前说明: 我不保证我提供的 API 地址可永久使用,也没有售后。要使用我的地址的话,请三思。
生成资源文章提示词
默认生成文章的提示词:
您是一位智能信息提取助手。您的任务是从给定的标题名+文件列表文本中提取信息,然后生成100-500字左右的介绍文章。
注意事项:
0. 请你注意,如果你无法生成文章,请直接返回“无”。
1. 除了文章内容,你不应该返回其它任何文字。
2. 你返回的内容应该以中文为主。
3. 请您基于事实生成,若无意义,请直接返回"无"。
4. 你可以适当结合你拥有的知识来补充生成文章。
5. 你生成的文字表达应该随意、客观,不应该有标准化的格式。
6. 生成的文章,请不要有总结性这种类AI文字。
7. 对于2024年的影视资源,请你直接返回“无”。生成标签提示词:
你是一个专业的文件分类器,需要通过给定的标题和文件名称列表为文件打标签。
这些标签应为中文2-4字或英文1个单词,如"影视"、"音乐"、"软件"等。
请根据文件名、标题和文件后缀,结合你的知识库进行分类。
这些标签应该尽可能的全面。
返回格式要求:纯文本、非markdown的JSON数组,如["标签1", "标签2", "标签3"]
注意忽略文件列表中明显是广告的文件名。通过内容生成二维码
有时候,没有 cdn 来保存图片,或者图片太大,不适合放在页面中,可以通过此功能,将内容生成二维码;
比如:个人微信号、公众号二维码,这些都可以是通过解析官方二维码的内容,然后将内容填进去,系统自动生成二维码;
资源数量展示模板
支持的变量:
%total%: 资源总数%today%: 今日新增资源数%user_total%: 用户总数 (预计在版本>=0.5.5添加)
找回密码内容
支持的变量:
%code%: 验证码%username%: 用户名%email%: 邮箱地址
注册用户验证内容
支持的变量:
%code%: 验证码- `
资源名称净化
该功能预计在版本>0.5.5中升级,将支持大部分正则表达式;
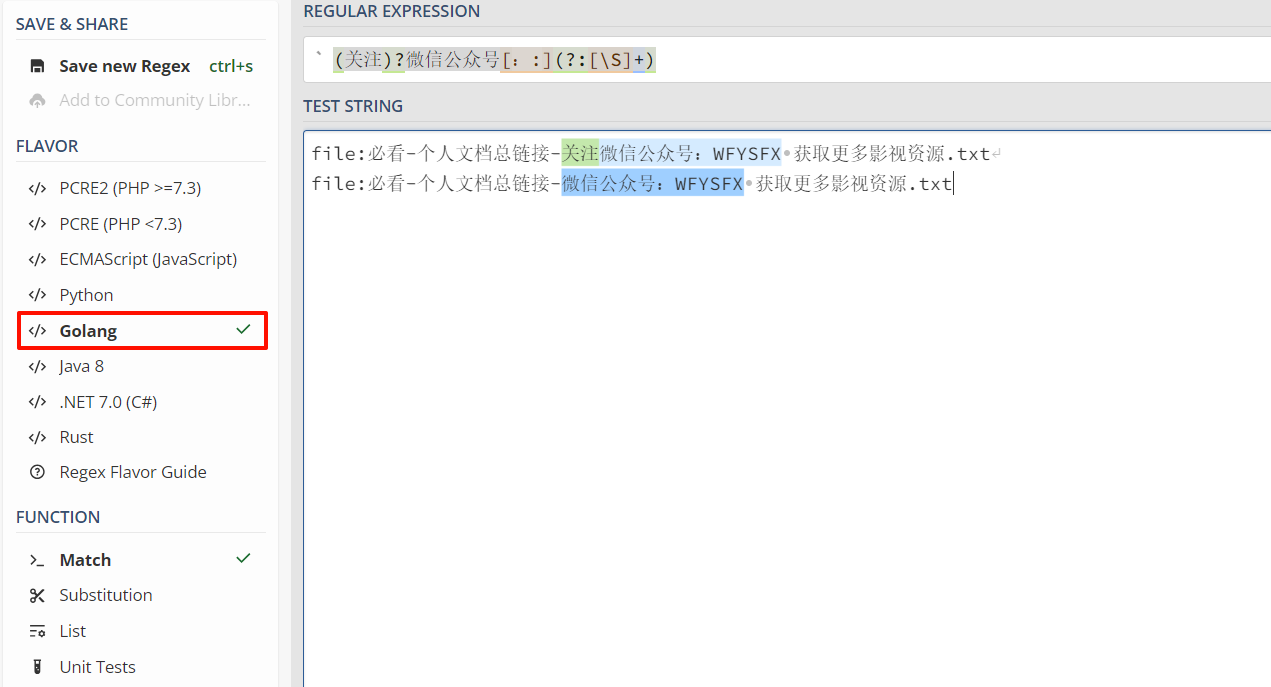
在线测试地址:https://regex101.com/
请选择 Golang 语言,然后将正则表达式填入,然后测试;
如果你不懂正则表达式,可以直接填入你想屏蔽的词,比如:
公众号
QQ
微信给几个正则例子:
(关注|微信)?公众号[::]?(?:[\S]+)
【公众号[::](?:[\S]+)】
^(\d+|\w)[\s-]*有想屏蔽的一些内容,可以联系帮忙添加正则;